Q-learning (Reinforcement Learning) 1 에서
현실세계, 확률적으로 행동하는 적이 있는 게임 환경 등에서 T(s,a,s')와 R(s,a,s')을 알지 못해도 V(s)와 Q(s,a)를 학습할 수 있는 방법이 Q-learning이며, Q-learning은 실제 환경, 게임에 들어가서 직접 행동을 취함으로써(불구덩이에 몸을 던짐으로써) Q(s,a)와 V(s)를 학습하는 'Online learning'이라고 설명했다.
이 학습 방법을 활용하면 항상 최적의 행동 a를 취하지 않고도(초기에는 최적의 행동이 무엇인지 조차 모름) 심지어는 확률적으로 행동을 취해도 model과 sample간의 차이를 기존 모델에 반영함으로써 최적의 Q(s,a)와 V(s)를 얻을 수 있다고도 했다.

하지만 환경이 매우 커서 Q(s, a) 값을 테이블에 저장하고, 이를 지속적으로 업데이트 하는 것이 공간 비효율적이라는 문제점을 해결하기 위해 agent가 처한 상태 s의 feature를 파악하고, 이를 통해 상태 s를 일반화(generalize)한 뒤, 각 feature별 가중치를 곱하는 방식인 Approximate Q-learning을 활용할 수 있음을 언급했고, 2편 글에서는 Approximate Q-learning에 대해 설명할 것이다.
Approximate Q-learning
Approximate Q-learning이란 Q(s,a) 테이블을 모두 저장하고 관리하는 대신, 이전의 경험을 기반으로 현재의 상황을 일반화하여 해석함으로써 각 상황에서 최적의 행동을 취할 수 있도록 학습하는 방법이다. 상황을 일반화 하기 위해서는 'Feature'와 'Weight'을 활용할 수 있고, Pacman 게임 예시로 알아보자.

Feature
Feature는 agent가 상태 s에서 마주하게 된 상황에 대한 정보이자, 특성값이다. Pacman게임의 경우 다음과 같은 특성값이 있을 수 있다.
- 가장 가까운 ghost와의 거리
- 가장 가까운 food와의 거리
- Ghost의 수
- 남은 food의 수
위 예시 외에도 상태 s에서 파악할 수 있는 환경에 대한 정보는 더 있을 것이다.
Weight
Weight은 각 특성값에 대한 가중치로, 해당 특성이 얼마나 중요한 특성인지를 정의한다. 가장 가까운 ghost와의 거리(dTg), 가장 가까운 food와의 거리(dTf)를 예시로 weight을 이해해보자면, Ghost가 멀수록, food가 가까울 수록 좋은 상태 s임을 꽤나 직관적으로 이해할 수 있다. Pacman 게임은 ghost에게 먹히지 않고 food를 최대한 많이 먹어야 점수를 최대화 할 수 있는 게임이기 때문이다.
그렇다면 dTg와 dTf에 대한 가중치는 활용하여 어떻게 Q(s,a)와 V(s)를 도출할 수 있을까? 바로 'Linear Value Function'을 통해 도출할 수 있다.
Linear Value Function
아래 예시에서 가중치 WdTg와 WdTf를 동일하게 5로 설정해보았다.
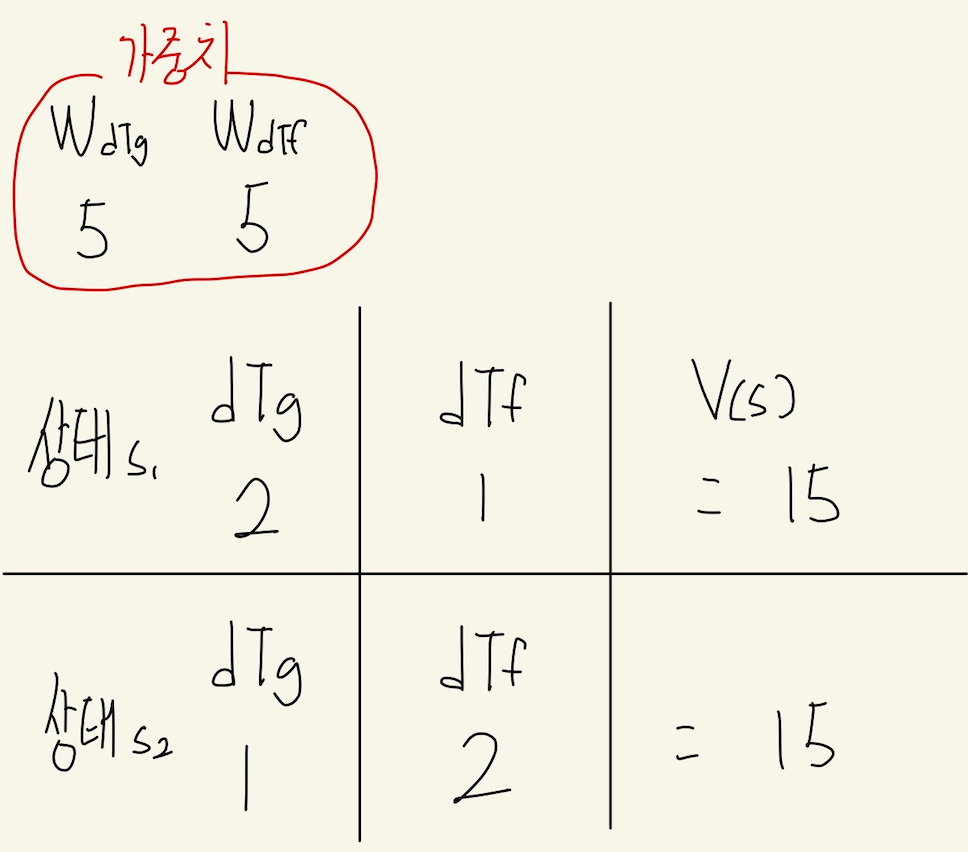
상태 s1은 ghost가 food보다 1만큼 가깝고, s2는 그 반대이다.
위 예시에서 가중치와 각 상태 V(s)의 연관성은 무엇인지 유추할 수 있을까?
.
.
.
V(s)는 사실 다음과 같다.
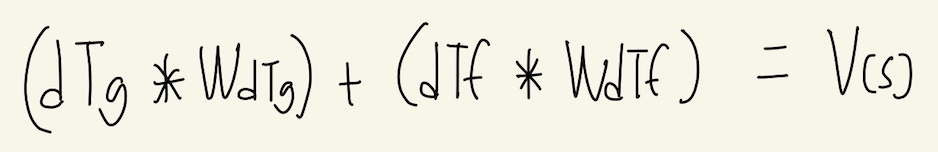
각 feature에 weight을 곱한 뒤, 이를 모두 더한 결과가 상태 s에 대한 V(s)이고, 이것이 바로 Linear Value Function이다.
Approximate Q-learning의 목표가 무엇이었나? 바로 과거의 경험을 기반으로 상태 s의 상황을 일반화하여, 상태 s에서 최적의 행동을 취하는 것이다. V(s)에 대한 값은 도출했으니, 각 상태 s와 행동 a에 대해서도 그 quality(Q(s,a))를 측정하여 최적의 행동이 무엇인지도 알아야 한다. 다행히도 Q(s,a)를 구하는 방법은 V(s)를 구하는 방법과 동일하다.
따라서 V(s)와 Q(s,a)를 구하는 식은 다음과 같이 정의할 수 있고, 각 상태 s를 일반화하기 위한 재료가 모두 준비되었다.
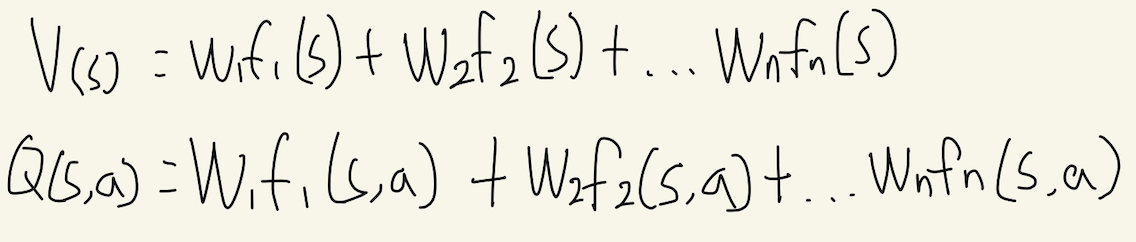
하지만 조금 더 디테일한 부분을 이해하기 위해 다시 예시로 돌아가보자.
예시에서 우리는 WdTg와 WdTf에 동일한 가중치 5를 설정했다.
하지만 이렇게 하니 ghost가 1만큼 가까운(잡아먹히기 딱 좋은) 상태 s1와 food가 1만큼 가까운 상태 s2가 동일한 V(s)를 갖는다. Agent는 V(s)를 기반으로 취할 행동 a를 결정하는데, 이와 같은 가중치로는 게임의 목표인 '잡아먹히지 않고, 최대한 food를 많이 먹는 것'을 달성할 수 없다.
따라서 다음과 같이 WdTf를 -5로 설정해보았다.

이때 agent는 어떤 상태 s를 더 좋은(V(s)가 더 큰) 상태로 인식할까? 바로 음식이 1만큼 가까운 상태 s1이다.
이와 같이 가중치를 조정함으로써 agent가 상태 s를 일반화하여 취할 행동 a를 결정할 때 어떤 행동을 취하는 것이 목표를 달성할 수 있는 행동인지 정의할 수 있겠다.
마지막으로 한 가지가 더 남았다!
Q-learning에서 model과 sample간의 차이를 더함으로써 optimal한 값에 가까워졌던 것이 Approximate Q-learning에서도 그대로 적용된다. 한 가지 차이점은 Approximate Q-learning에서는 업데이트 할 Q(s,a) 테이블이 없기 때문에 가중치를 업데이트한다.
sample과 model의 차이를 다음과 같다고 할 때,
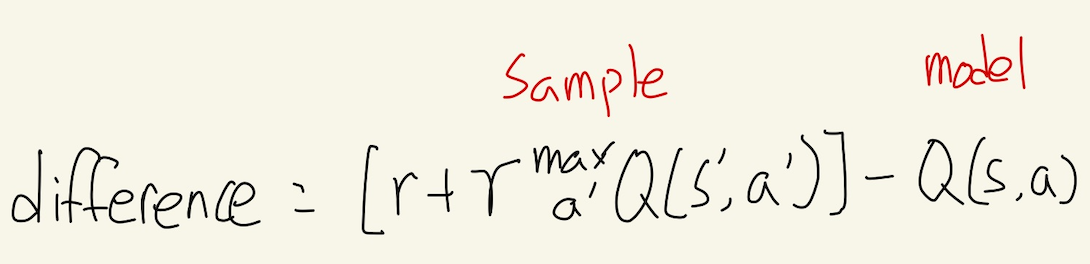
Q-learning과 Approximate Q-learning의 차이는 다음과 같다.

결론
Approximate Q-learning이
T(s,a,s')와 R(s,a,s')을 알지 못해도
Q(s,a), V(s)를 저장할 충분한 메모리 공간이 없어도
Agent가 매번 최적의 행동을 하지 않아도
게임 상황, 현실세계의 상황을 일반화하여 행동을 취할 수 있도록 학습하는 방법임을 알아보았다.
이는 실제로도 강화학습 분야의 기본이 되는 개념이라 꼭 이해하고 넘어가야 했다. 강화학습 혹은 딥러닝 분야 연구를 하지 않더라도, Q-learning에 대해 이해하고 있으면 앞으로 강화학습, 딥러닝 등 인공지능 관련 연구들, 산업에서의 적용 사례들을 이해할 때 큰 도움이 될 것이라 생각한다.
본인은 이 개념을 명확히 이해하는 데 몇주가 걸려서 글로 정리하면서 이해를 확인하고자 했는데, 글을 쓰기 전에 비해 명확해진 것 같다.
강화학습 공부를 이제 막 시작하면서 나와 같은 어려움을 겪는 분들에게 조금이나마 도움이 되었으면 한다.
참고자료
Reinforcement Learning 1, CS188 Berkely
Reinforcement Learning 2, CS188 Berkely
김현우 교수님 인공지능 강의, COSE361 고려대학교
+ Q-learning 1편
Q-learning (Reinforcement Learning) 1
Q-learning (Reinforcement Learning) 1
Q-learning은 모델 없이 학습하는 강화학습 기법 중 하나이다. 배경지식 Agent는 상태 s ∈ S 에서 행동 a ∈ A 를 취할 수 있고, 한 agent가 상태 s에서 행동 a를 취했을 때 s' 으로 이동할 확률은 T(s, a, s')
omins.tistory.com
'CS > AI' 카테고리의 다른 글
| Q-learning (Reinforcement Learning) 1 (0) | 2022.06.18 |
|---|

댓글